安達研究室では,情報検索およびデータベースについて主に研究しています.
爆発的に増大している情報を効率良く扱い,最適な情報を容易に得られるように,以下の課題に取り組んでいます.
情報検索
情報検索システムは,ユーザからの問い合わせに適合する文書を探しだし,それら文書を取得したいという要求を満たすためのシステムである.しかしながら,ユーザの入力する検索語によっては,検索結果にユーザの期待しない情報が混在してしまう.これを解消するため,検索語,検索結果それぞれについて曖昧性を解消するための手法を提案している.また,P2Pのような分散環境においても集中型検索システムと同等以上の性能や機能を実現するための手法を提案している.
検索語の曖昧性解消
現在の検索エンジンでは,入力される検索語に曖昧性があるため,結果のランキング出力の中に,質問者の期待していないノイズ文書が混在することが避けられない.例えば,『ジャガー』というキーワードで検索すると,車,MacOS,動物,ミシン,プロレスラー,漫画などの文書が含まれてしまい,探したい情報が埋もれてしまう.
本研究は,多様な内容を含む検索結果の中から,質問者の期待する内容に特化した検索結果を得られるような検索語を提示することを目指した.特定のトピックに強く関係する単語を抽出するため,特定の語群とのみよく共起する単語の重みの定式化と,トピックを表す単語クラスタリング手法を提案した.
同姓同名の曖昧性解消
人名での検索結果には,同姓同名の複数人の結果が含まれることが多い.有名人を例に挙げると,『マイケル・ジャクソン』は歌手とビール専門家が含まれる.
本研究は,有名人だけでなく一般の人も対象にした同姓同名の文書の区別を目指した.人に関する文書がもつトピックに注目し,知識ベースを用いた文書ベクトルの修正と,LDA手法を使ったトピック抽出手法を提案した.
検索結果の絞り込み
検索エンジンにおける検索結果の順位は,大多数の人が満足するようにつくられている.これをさらにユーザの望ましい結果にするには,検索結果にユーザが与えるフィードバックを最大限に活かすことが重要である.
本研究は,検索結果に簡単な評価を加えるだけで,検索結果の順位をユーザに最適なものに改善することを目指した.ユーザが望ましくないと評価した項目の特徴を抽出する制約付きクラスタリングと,新しい順位を生成する適合性フィードバックを提案した.
P2P情報検索
各種テキストやセンサからの実空間情報など,加速的に増え続ける情報を検索対象にするには,スケーラブルな検索基盤が必要である.
本研究は,P2Pネットワークを使った情報検索技術(P2P IR)に注目し,情報爆発やユビキタス環境を見据えた大規模でかつ安定性の高い検索基盤の構築を目指した.単語の出現頻度の特徴を利用した,分散管理する検索索引や文書データの配置方法を提案した.
電子文書の図表検索
過去に蓄積されてきた文書をOCRでデジタル化する取り組みがなされている.これらを電子図書館や検索システムなどで活用するには,文字列の抽出だけでなく,文書の構造も抽出する必要がある.
本研究は,電子文書の図表検索をアプリとして見据え,非構造な電子文書からの精度の高い文書構造抽出を目指した.文書構造抽出技術の提案に加え,抽出結果をもとに図表とその説明文を判別し,図表検索システムを構築した.
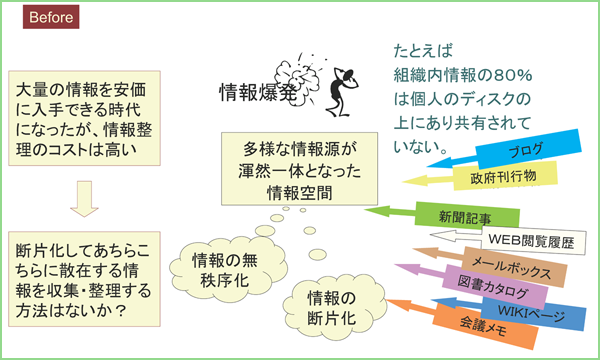
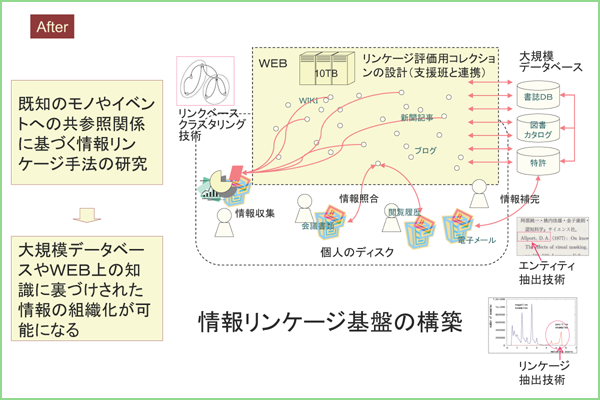
情報リンケージ
インターネット上で公開される各種テキストや個人・組織が管理する文書を対象として、関連する情報を結び付ける「情報リンケージ」プラットフォームの実現を目指す。 本研究で提案する情報リンケージ技術とは、無秩序に拡大する大量情報の中からその場で自分の必要とする情報を的確に取り出し、わかりやすく提示する新しいアプローチであり、 従来からの情報検索、フィルタリング、質問応答の技術と情報統合を組み合わせ、新しい情報獲得手法として体系化を図ろうとするものである。 これによって、たとえば独立に運用されるポータルサイトからの情報を統合して、包括的で偏りのないレビューを利用者に即座に提示するといった機能が実現される。 情報リンケージの対象としては、本研究では特に、適用範囲の重要さと研究期間内での実現可能性を鑑み、本や人物や製品といった具体物(モノ)および台風や選挙といった事件(イベント)に絞り込む、 情報リンケージを実現する技術を提案し、知的な活動に寄与する実用技術としてプロトタイプ実現に取り組む。
本研究は,国立情報学研究所と共同で取り組んでいる.
書誌情報のマッチング
論文検索サイトでは,各論文の被引用数の算出は重要である.しかしながら,引用文字列には著者名やページ数の省略,雑誌名などの略称の記述が頻繁に起き,同一の文献を指しているか否かの判定が困難である.
本研究では,機械学習を用いて引用文字列の同一性の判定精度を向上させた.引用文献の記述方法が異なる多くの分野に適用できる手法にすべく,CRFにより書誌情報のフィールド分類を行い,その後に類似度を計算する手法を提案した.
類似検索
メトリック空間(距離空間)で扱えるオブジェクトを対象にした類似検索索引に関する研究である.我々は,オブジェクトの分布の抽出結果をもとにしたデータ空間の分割により,検索問い合わせ処理を軽減する索引手法を提案した.本索引技術は,データ間の距離(類似度)が三角不等式などの距離の公理を満たすものであれば,いかなるデータも扱える.例えば,ユークリッド距離やジャカード係数,編集距離といった距離関数で類似性を定義できるベクトルや集合データ,文字列などを対象にした類似検索システムに適用できる.
ネットワーク構造データのクラスタリングと要約
地下鉄の路線図やSNSにおける人間関係など,ネットワーク構造データとして記述されるデータが多数存在する.ネットワーク構造データはオブジェクト間の関係性を記述,視覚化するのに適しているとされるが,複雑で大規模なものになるにつれて大域的な理解が困難になっていく.
本研究では,複雑で大規模なネットワーク構造データを簡易的な記述に変換することを目指した.データ中のノードのハブ機能を考慮した定式化と,ネットワーク構造データの要約手法を提案した.